
使用 Kubernetes 部署 RabbitMQ 集群
一、RabbitMQ 简介
以熟悉的电商场景为例,如果商品服务和订单服务是两个不同的微服务,在下单的过程中订单服务需要调用商品服务进行扣库存操作。按照传统的方式,下单过程要等到调用完毕之后才能返回下单成功,如果网络产生波动等原因使得商品服务扣库存延迟或者失败,会带来较差的用户体验,如果在高并发的场景下,这样的处理显然是不合适的,那怎么进行优化呢?这就需要消息队列登场了。
消息队列提供一个异步通信机制,消息的发送者不必一直等待到消息被成功处理才返回,而是立即返回。消息中间件负责处理网络通信,如果网络连接不可用,消息被暂存于队列当中,当网络畅通的时候在将消息转发给相应的应用程序或者服务,当然前提是这些服务订阅了该队列。如果在商品服务和订单服务之间使用消息中间件,既可以提高并发量,又降低服务之间的耦合度。
RabbitMQ是一个开源的消息代理的队列服务器,用来通过普通协议在完全不同的应用之间共享数据。
1.1 RabbitMQ 的特点
开源、性能优秀,速度快,稳定性保障提供可靠性消息投递模式、返回模式与Spring AMQP完美整合,API丰富集群模式丰富,表达式配置,HA模式,镜像队列模型保证数据不丢失的前提做到高可靠性、可用性
1.2 典型应用场景
- 异步处理:把消息放入消息中间件中,等到需要的时候再去处理。
- 流量削峰:例如秒杀活动,在短时间内访问量急剧增加,使用消息队列,当消息队列满了就拒绝响应,跳转到错误页面,这样就可以使得系统不会因为超负载而崩溃。
- 日志处理;(不过一般日志处理都使用Kafka这种消息队列)
- 应用解耦:假设某个服务A需要给许多个服务(B、C、D)发送消息,当某个服务(例如B)不需要发送消息了,服务A需要改代码再次部署;当新加入一个服务(服务E)需要服务A的消息的时候,也需要改代码重新部署;另外服务A也要考虑其他服务挂掉,没有收到消息怎么办?要不要重新发送呢?是不是很麻烦,使用MQ发布订阅模式,服务A只生产消息发送到MQ,B、C、D从MQ中读取消息,需要A的消息就订阅,不需要了就取消订阅,服务A不再操心其他的事情,使用这种方式可以降低服务或者系统之间的耦合。
1.3 RabbitMQ集群节点之间是如何相互认证的:
- 通过Erlang Cookie,相当于共享秘钥的概念,长度任意,只要所有节点都一致即可。
- rabbitmq server在启动的时候,erlang VM会自动创建一个随机的cookie文件。cookie文件的位置是/var/lib/rabbitmq/.erlang.cookie 或者 /root/.erlang.cookie,为保证cookie的完全一致,采用从一个节点copy的方式。
Erlang Cookie是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的Erlang Cookie。具体的目录存放在/var/lib/rabbitmq/.erlang.cookie。
说明:这就要从rabbitmqctl命令的工作原理说起,RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证。
1.4 RabbitMQ集群模式
- 单机模式
- 普通集群模式(无高可用性)
- 镜像集群模式(高可用性),最常用的集群模式。
1.5 RabbitMQ集群故障处理机制:
- rabbitmq broker集群允许个体节点down机,
- 对应集群的的网络分区问题( network partitions)
RabbitMQ集群推荐用于LAN环境,不适用WAN环境;
要通过WAN连接broker,Shovel or Federation插件是最佳的解决方案;Shovel or Federation不同于集群。
1.6 RabbitMQ节点类型
- RAM node:只保存状态到内存。内存节点将所有的队列、交换机、绑定、用户、权限和vhost的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
- Disk node:将元数据存储在磁盘中。单节点系统只允许磁盘类型的节点,防止重启RabbitMQ的时候,丢失系统的配置信息。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。RabbitMQ集群中,只需要一个磁盘节点来保存状态就足够了;如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
问题说明:
- RabbitMQ要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。
- 如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
解决方案:设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。
1.7 RabbitMQ集群的节点运行模式:
- 为保证数据持久性,当前所有node节点跑在disk模式。
- 如果今后压力大,需要提高性能,考虑采用ram模式。
R
二、RabbitMQ 集群说明
本案例采用 “镜像模式”,即队列为镜像队列,队列消息存在集群的每个节点上。
2.1、版本说明
因为考虑到较早版本rabbitmq在k8s上的集群部署是使用autocluster插件去调用kubernetes apiserver来获取rabbitmq服务的endpoints,进而获取node节点信息,并自动加入集群,但是现在autocluster已不再更新了,并且只支持3.6.x版本,故而放弃这种方式。
对于3.7.x或更新的版本,现在市场主流是使用 peer discovery subsystem来构建rabbitmq-cluster,参考这里。
这边的版本要求: RabbitMQ 3.9.15Erlang 24.3.3
2.2、部署方式
在Kubernetes上搭建RabbitMQ有4种部署方法:
- IP模式
- Pod与Server的DNS模式
- Statefulset 与Headless Service模式
- hostname模式
这里选择StatefulSet与Headless Service模式部署有状态的RabbitMQ集群。
2.3、使用NFS配置StatefulSet的动态持久化存储
rabbitmq属于有状态的服务,即每个服务上存储的内容都不一样,对于有状态的服务,k8s推荐我们使用StatefulSet控制器。
rabbitmq中的部分信息需要持久化,持久化内容使用nfs进行存储,并使用storageclass动态分配pv。
三、RabbitMQ 集群部署
3.1、思路梳理
使用官方提供的 RabbitMQ Cluster Operator for Kubernetes。
Open source RabbitMQ Cluster Kubernetes Operator by VMware。
3.2、官方文档快速部署
官方提供了快速部署的例子,只需要两步,这里我们仅作参考,后面我们参考内网离线镜像部署的方案。
部署 RabbitMQ Cluster Operator
1 | kubectl apply -f https://github.com/rabbitmq/cluster-operator/releases/latest/download/cluster-operator.yml |
部署 RabbitMQ Cluster
1 | kubectl apply -f https://raw.githubusercontent.com/rabbitmq/cluster-operator/main/docs/examples/hell |
3.3、准备离线镜像
此过程为可选项,离线内网环境可用,如果不配置内网镜像,后续的资源配置清单中注意更改容器的 image 为默认值。
在一台能同时访问互联网和内网 镜像仓库的服务器上进行下面的操作。
1 | # 1、登入远程仓库 |
3.4、资源配置清单
3.4.1、cluster-operator.yml
通过官网获取 RabbitMQ Cluster Operator 部署资源配置清单「cluster-operator.yml」
1 | # 创建项目目录 |
修改 RabbitMQ Cluster Operator image 为内网镜像
1 | sed -i 's#rabbitmqoperator#远程仓库地址/rabbitmqoperator#g' cluster-operator.yml |
如果仓库有密码记得添加key
1 | imagePullSecrets: |
3.4.2、rabbitmq-cluster.yaml
RabbitMQ Cluster 部署资源清单「rabbitmq-cluster.yaml」
1 |
|
更多配置参数和配置示例,请参考 官方文档
3.4.3、管理页面的外部访问服务 rabbitmq-cluster-external.yaml
1 |
|
3.5、部署资源
部署 RabbitMQ Cluster Operator
1 | [root@devops-master k8s-yaml]# kubectl apply -f rabbitmq/cluster/cluster-operator.yml |
注意 rabbit-system namespec 建出来之后要给这个空间添加访问私有仓库得key,才能下载镜像
1 | kubectl -n rabbitmq-system create secret \ |
部署 RabbitMQ Cluster
1 | [root@devops-master k8s-yaml]# kubectl apply -f rabbitmq/cluster/rabbitmq-cluster.yaml |
部署管理页面外部访问服务
1 | [root@devops-master k8s-yaml]# kubectl apply -f rabbitmq/cluster/rabbitmq-cluster-external.yaml |
四、验证
4.1、RabbitMQ Cluster Operator Deployment
1 | [root@devops-master k8s-yaml]# kubectl get deployments -n rabbitmq-system -o wide |
4.2、RabbitmqClusters
1 | [root@devops-master k8s-yaml]# kubectl get rabbitmqclusters -n devops |
4.3、StatefulSet
1 | [root@devops-master k8s-yaml]# kubectl get sts -o wide -n devops |
4.4、Pods
1 | [root@devops-master k8s-yaml]# kubectl get pods -o wide -n devops |
4.5、Services
1 | [root@devops-master k8s-yaml]# kubectl get svc -n devops -o wide |
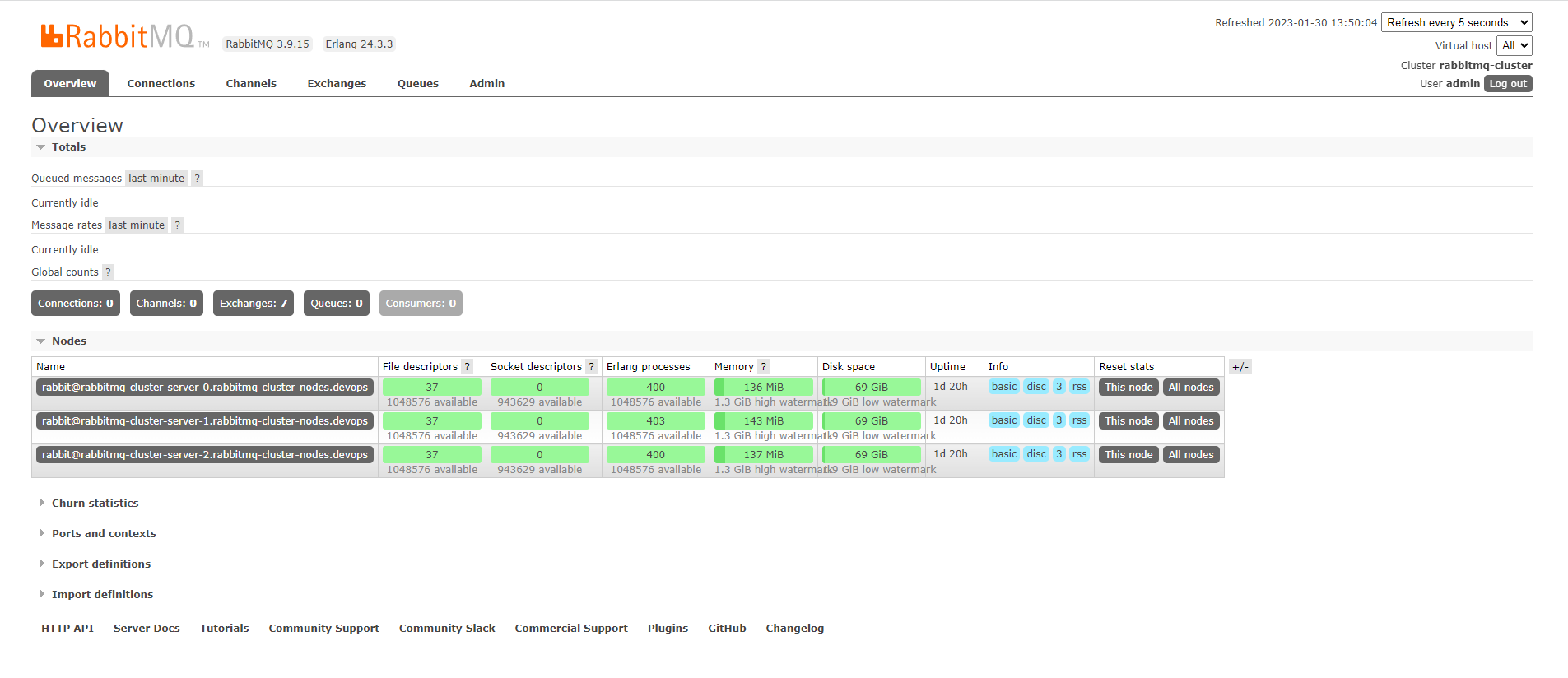
4.6、图形化管理界面
五、清理资源
清理 RabbitmqClusters
1 | [root@devops-master k8s-yaml]# kubectl delete rabbitmqclusters rabbitmq-cluster -n devops |
清理管理页面外部服务
1 | [root@devops-master k8s-yaml]# kubectl delete svc rabbitmq-cluster-external -n devops |
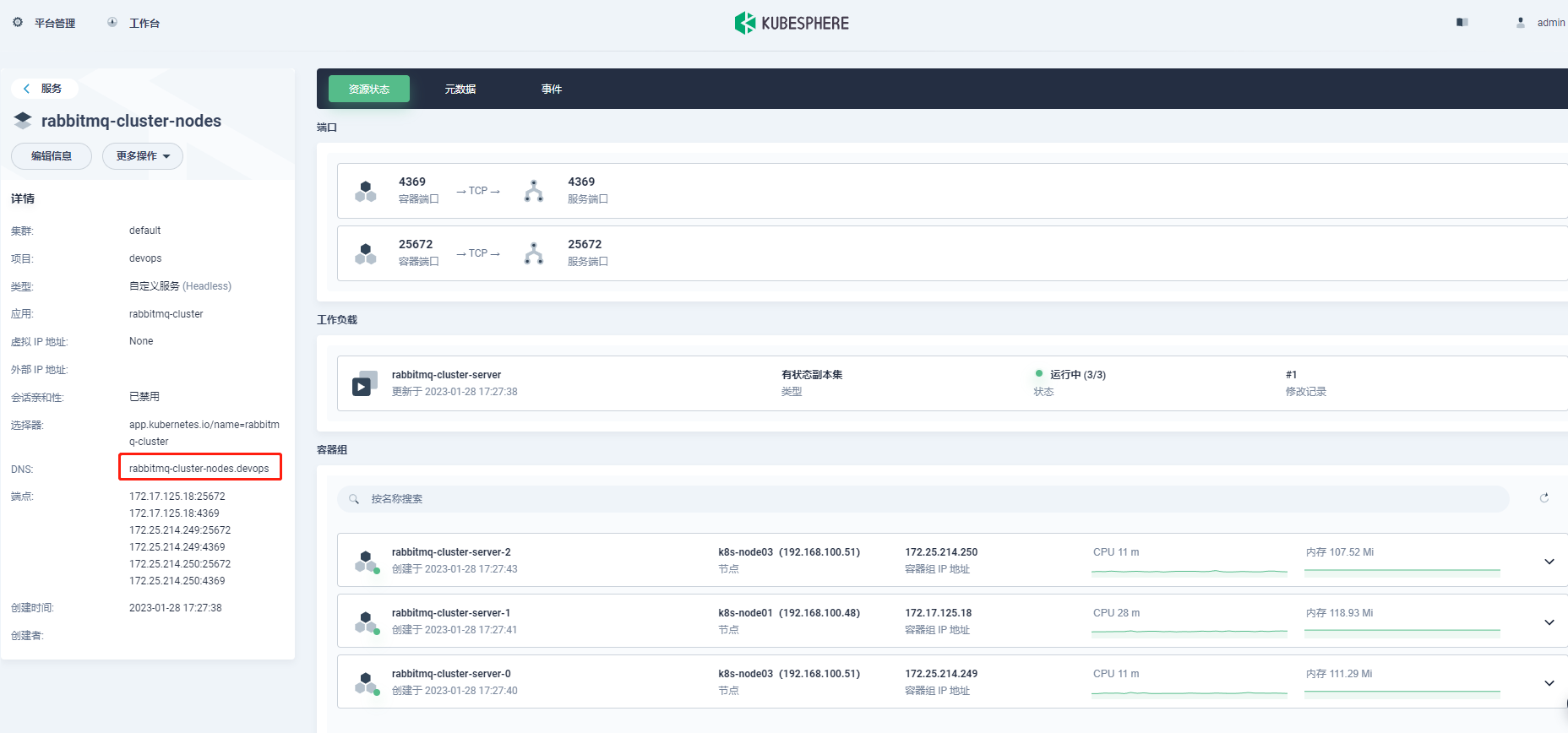
五、客户端访问RabbitMQ集群地址
客户端连接RabbitMQ集群地址:
连接方式:
- 客户端可以连接RabbitMQ集群中的任意一个节点。如果一个节点故障,客户端自行重新连接到其他的可用节点;
- 也就是说,RabbitMQ集群有”重连”机制,但是这种集群连接方式对客户端不透明,不太建议这种连接方式。
推荐方式:给客户端提供一个统一的透明的集群连接地址
rabbitmq-cluster-nodes.devops.svc.cluster.local:5672



