
prometheus-grafana介绍安装
一、简介
Prometheus监控系统中,采集与警报是分离的。警报规则在 Prometheus 定义,警报规则触发以后,才会将信息转发到给独立的组件 Alertmanager ,经过 Alertmanager r对警报的信息处理后,最终通过接收器发送给指定用户,另外在 Alertmanager 中没有通知组的概念,只能自己对软件重新Coding,或者使用第三方插件来实现。
Alertmanager工作机制
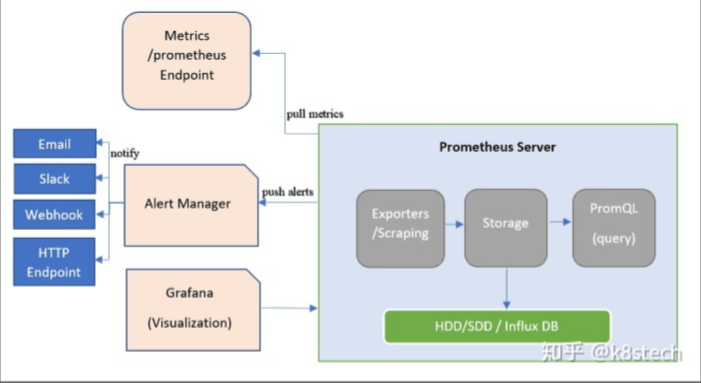
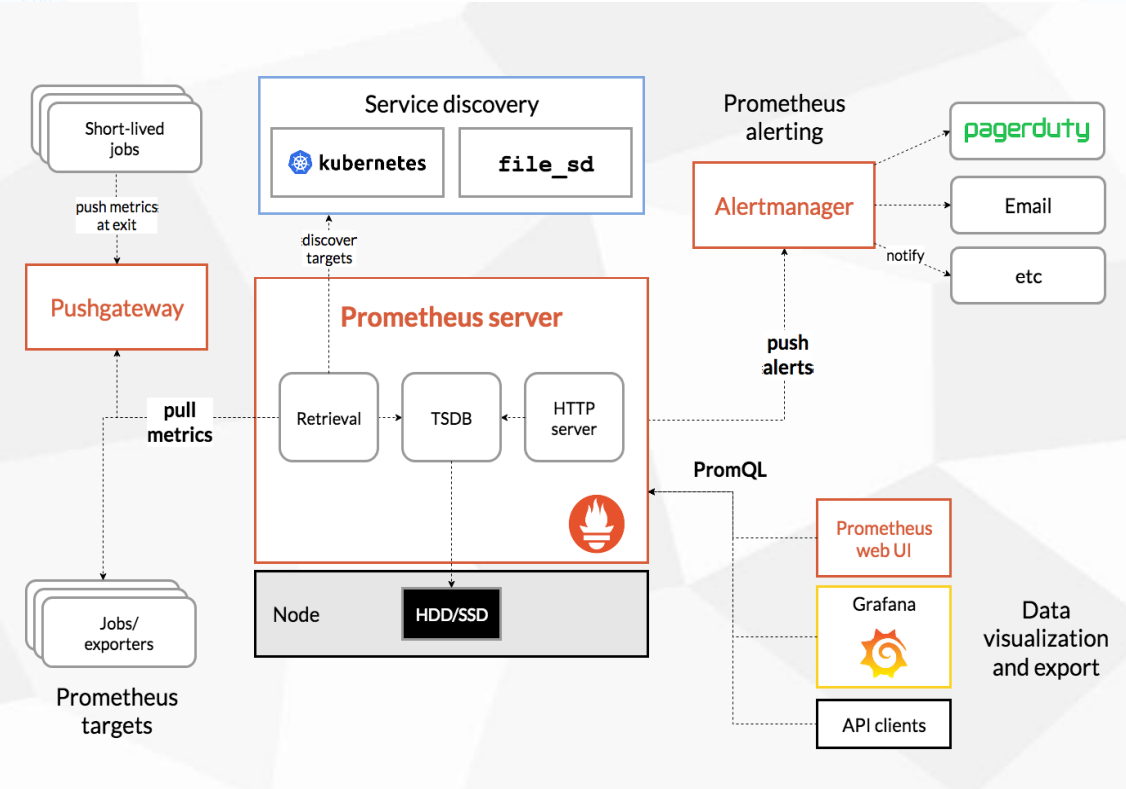
在Prometheus生态架构里,警报是由独立的俩部分组成,可以通过上图很清晰的了解到 Prometheus 的警报工作机制。其中 Prometheus 与 Alertmanager 是分离的俩个组件。我们使用Prometheus Server端通过静态或者动态配置 去拉取 pull 部署在k8s或云主机上的各种类别的监控指标数据,然后基于我们前面讲到的 PromQL 对这些已经存储在本地存储 HDD/SSD 的 TSDB 中的指标定义阈值警报规则 Rules 。Prometheus会根据配置的参数周期性的对警报规则进行计算, 如果满足警报条件,生产一条警报信息,将其推送到 Alertmanager 组件,Alertmanager 收到警报信息之后,会对警告信息进行处理,进行 分组 Group 并将它们通过定义好的路由 Routing 规则转到 正确的接收器 receiver, 比如 Email Slack 钉钉、企业微信 Robot(webhook) 企业微信 等,最终异常事件 Warning、Error通知给定义好的接收人,其中如钉钉是基于第三方通知来实现的,对于通知人定义是在钉钉的第三方组件中配置。
二、AlertManager的三个概念
分组
Grouping 是 Alertmanager 把同类型的警报进行分组,合并多条警报到一个通知中。在生产环境中,特别是云环境下的业务之间密集耦合时,若出现多台 Instance 故障,可能会导致成千上百条警报触发。在这种情况下使用分组机制, 可以把这些被触发的警报合并为一个警报进行通知,从而避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位。
举个栗子,在Kubernetes集群中,运行着重量级规模的实例,即便是集群中持续很小一段时间的网络延迟或者延迟导致网络抖动,也会引发大量类似服务应用无法连接 DB 的故障。如果在警报规则中定义每一个应用实例都发送警报,那么到最后的结果就是 会有大量的警报信息发送给 Alertmanager 。
作为运维组或者相关业务组的开发人员,可能更关心的是在一个通知中就可以快速查看到哪些服务实例被本次故障影响了。为此,我们对服务所在集群或者服务警报名称的维度进行分组配置,把警报汇总成一条通知时,就不会受到警报信息的频繁发送影响了。
抑制
Inhibition 是 当某条警报已经发送,停止重复发送由此警报引发的其他异常或故障的警报机制。在生产环境中,IDC托管机柜中,若每一个机柜接入层仅仅是单台交换机,那么该机柜接入交换机故障会造成机柜中服务器非 up 状态警报。再有服务器上部署的应用服务不可访问也会触发警报。 这时候,可以通过在 Alertmanager 配置忽略由于交换机故障而造成的此机柜中的所有服务器及其应用不可达而产生的警报。
在我们的灾备体系中,当原有集群故障宕机业务彻底无法访问的时候,会把用户流量切换到备份集群中,这样为故障集群及其提供的各个微服务状态发送警报机会失去了意义,此时, Alertmanager 的抑制特性就可以在一定程度上避免管理员收到过多无用的警报通知。
静默
Silences 提供了一个简单的机制,根据标签快速对警报进行静默处理;对传进来的警报进行匹配检查,如果接受到警报符合静默的配置,Alertmanager 则不会发送警报通知。
以上除了分组、抑制是在 Alertmanager 配置文件中配置,静默是需要在 WEB UI 界面中设置临时屏蔽指定的警报通知。
以上的概念需要好好理解,这样才可以轻松的在监控系统设计的时候针对警报设计的一些场景自行调整。
三、安装
部署安装
1 | ## 创建相关目录 |
启动报错
1 | alertmanager.service: main process exited, code=exited, status=217/USER |
指定的用户错误
配置文件/etc/systemd/system/alertmanager.service
User=prometheus 改成 User=root
访问
IP:9093
Alertmanager 参数
启动参数
| 参数 | 描述 |
|---|---|
| –config.file=”alertmanager.yml” | 指定Alertmanager配置文件路径 |
| –storage.path=”data/“ | Alertmanager的数据存放目录 |
| –data.retention=120h | 历史数据保留时间,默认为120h |
| –alerts.gc-interval=30m | 警报gc之间的间隔 |
| –web.external-url=WEB.EXTERNAL-URL | 外部可访问的Alertmanager的URL(例如Alertmanager是通过nginx反向代理) |
| –web.route-prefix=WEB.ROUTE-PREFIX | wen访问内部路由路径,默认是 –web.external-url |
| –web.listen-address=”:9093” | 监听端口,可以随意修改 |
| –web.get-concurrency=0 | 并发处理的最大GET请求数,默认为0 |
| –web.timeout=0 | web请求超时时间 |
| –cluster.listen-address=”0.0.0.0:9094” | 集群的监听端口地址。设置为空字符串禁用HA模式 |
| –cluster.advertise-address=CLUSTER.ADVERTISE-ADDRESS | 配置集群通知地址 |
| –cluster.gossip-interval=200ms | 发送条消息之间的间隔,可以以增加带宽为代价更快地跨集群传播。 |
| –cluster.peer-timeout=15s | 在同级之间等待发送通知的时间 |
| –log.level=info | 自定义消息格式 [debug, info, warn, error] |
| –log.format=logfmt | 日志消息的输出格式: [logfmt, json] |
| –version | 显示版本号 |
Alertmanager 配置文件
 闽ICP备2021007966号-1
闽ICP备2021007966号-1